关于如何编码神经网络的反向传播算法,我有几个问题:
我的网络拓扑是输入层,隐藏层和输出层 . 隐藏层和输出层都具有sigmoid功能 .
-
首先,我应该使用偏见吗?我应该在哪里连接网络中的偏差?我应该在隐藏层和输出层中每层放置一个偏置单元吗?输入层怎么样?
-
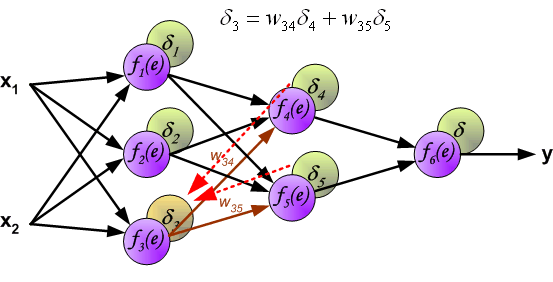
在这个link中,他们将最后一个delta定义为输入 - 输出,并且它们反向传播增量,如图所示 . 他们持有一张表,以便在以前馈方式实际传播错误之前放置所有增量 . 这是否与标准的反向传播算法有所不同? alt text http://galaxy.agh.edu.pl/~vlsi/AI/backp_t_en/backprop_files/img13.gif
-
我应该随着时间的推移减少学习因素吗?
-
如果有人知道,Resilient Propagation是在线还是批量学习技术?
{kind=link}
谢谢
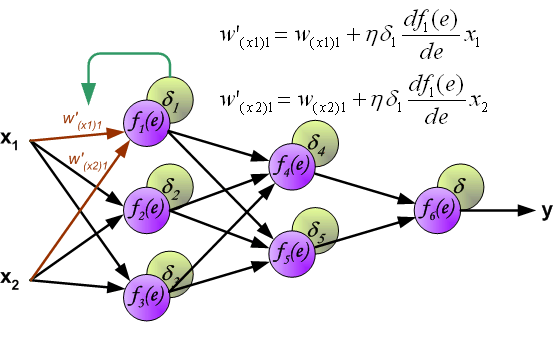
edit: 还有一件事 . 在下图中,假设我使用sigmoid函数,d f1(e)/ de是f1(e)* [1- f1(e)],对吧? alt text http://galaxy.agh.edu.pl/~vlsi/AI/backp_t_en/backprop_files/img14.gif
{kind=link}
2 回答
它有所不同 . 就个人而言,我没有看到很多偏见的原因,但我没有足够的研究NN来实际提出或反对他们的有效案例 . 我会尝试一下并测试结果 .
这是对的 . 反向传播首先计算增量,然后通过网络传播它们 .
是的 . 学习因素应随着时间的推移而降低 . 但是,使用BP,您可以达到局部的,不正确的平台,因此有时在第500次迭代时,将学习因子重置为初始速率是有意义的 .
我无法回答.....从未听说过关于RP的事情 .
你的问题需要更彻底地说明......你需要什么?泛化还是记忆?您是否期望复杂模式匹配数据集或连续域输入输出关系?这是我的0.02美元:
我建议你留下一个偏见的神经元,万一你需要它 . 如果NN认为不必要,则训练应将权重推至可忽略不计的值 . 它将连接到前面层中的每个神经元,但不连接到前一层中的任何神经元 .
据我所知,该等式看起来像标准的反向 .
很难概括您的学习率是否需要随着时间的推移而降低 . 该行为高度依赖于数据 . 你的学习率越小,你的训练就越稳定 . 但是,它可能会非常缓慢,特别是如果您使用脚本语言运行它,就像我曾经做过的那样 .
弹性backprop(或MATLAB中的RProp)应该处理在线和批量训练模式 .
我想补充一点,如果可能的话,您可能需要考虑其他激活功能 . sigmoid函数并不总是给出最好的结果......