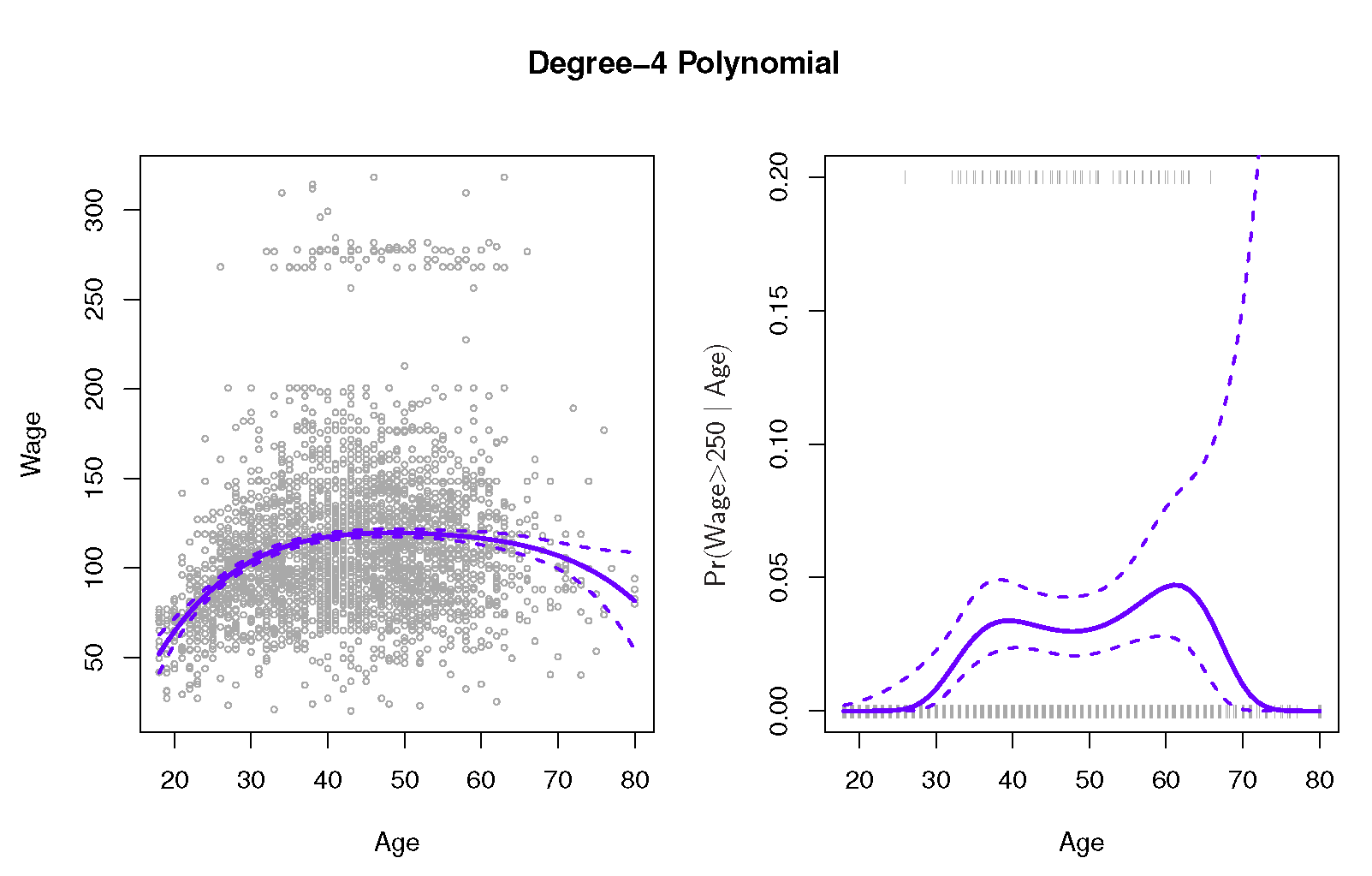
我正在尝试从“统计学习简介”重新创建一个情节,并且我试图重新创建该图的右侧面板(figure 7.1),该面板预测工资> 250的概率基于年龄为4的多项式相关的95%置信区间 . 如果有人关心,工资数据是here .
{kind=link}
我可以使用以下代码预测并绘制预测概率
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
from sklearn.preprocessing import PolynomialFeatures
wage = pd.read_csv('../../data/Wage.csv', index_col=0)
wage['wage250'] = 0
wage.loc[wage['wage'] > 250, 'wage250'] = 1
poly = Polynomialfeatures(degree=4)
age = poly.fit_transform(wage['age'].values.reshape(-1, 1))
logit = sm.Logit(wage['wage250'], age).fit()
age_range_poly = poly.fit_transform(np.arange(18, 81).reshape(-1, 1))
y_proba = logit.predict(age_range_poly)
plt.plot(age_range_poly[:, 1], y_proba)
但我对如何计算预测概率的置信区间感到茫然 . 我已经考虑过多次引导数据以获得每个时代的概率分布,但我知道有一种更简单的方法,这是我无法掌握的 .
我有估计的系数协方差矩阵和与每个估计系数相关的标准误差 . 如果给出这些信息,我将如何计算上图中右侧面板所示的置信区间?
谢谢!
1 回答
您可以使用delta method查找预测概率的近似方差 . 也就是说,
其中
gradient是模型系数的预测概率导数的向量,cov是系数的协方差矩阵 .事实证明,Delta方法可以渐近地用于所有最大似然估计 . 但是,如果您有一个小的训练样本,渐近方法可能无法正常工作,您应该考虑自举 .
以下是将delta方法应用于逻辑回归的玩具示例:
它绘制了以下精美图片:

对于您的示例,代码将是
它会给出如下图片
看起来非常像一个里面有大象的蟒蛇 .
您可以将它与bootstrap估计值进行比较:
delta方法和bootstrap的结果看起来几乎相同 .
然而,本书的作者走的是第三种方式 . 他们使用的事实
proba = np.exp(np.dot(x,params))/(1 np.exp(np.dot(x,params)))
并计算线性部分的置信区间,然后用logit函数进行变换
所以他们得到了不同的间隔:
这些方法产生了如此不同的结果,因为它们假定正常分布的不同事物(预测概率和对数概率) . 也就是说,delta方法假设预测的概率是正常的,并且在书中,对数概率是正常的 . 事实上,它们在有限样本中都不是正常的,但它们都收敛于无限样本中,但它们的方差同时收敛于零 . 最大似然估计对重新参数化不敏感,但它们的估计分布是,这就是问题所在 .